
Comprehensive data services, tailored to you
From start-ups to enterprises, and from resource augmentation to full project teams, we deliver solutions that fit your needs. And if we’re not the right partner for a challenge, we’ll say so, because transparency is part of how we work.
Azure data platform design
Azure provides enterprise-scale data solutions and reference architectures for a unified, cloud-native foundation for storing, processing, and analysing enterprise data. By leveraging Synapse Dedicated or Serverless SQL Pools, Azure Data Lake Gen2, and Power BI, it enables scalable performance, cost efficiency, and seamless integration with advanced analytics services.

Infrastructure design
We design and implement robust Azure cloud infrastructures tailored to your business needs. Our approach ensures scalability, security, and cost efficiency, while aligning with Microsoft best practices. From networking and storage to compute and identity management, we build a strong foundation that supports long-term growth and reliability.
Solution reference architecture design
Our team develops Azure solution reference architectures that provide clear, proven blueprints for complex data and analytics initiatives. These frameworks accelerate delivery, reduce risk, and ensure consistency across projects. By leveraging industry standards and Azure-native services, we help clients achieve faster time-to-value with reliable, enterprise-ready solutions.
Data architecture and models
We create modern data architectures and models on Azure that transform raw data into structured, actionable insights. This includes designing pipelines, warehouses, and semantic models optimised for performance and scalability. Our focus is on enabling organisations to unlock the full potential of their data for decision-making and innovation.
Dimensional data models
Well-known data modelling technique, ideal for business intelligence and reporting where data is structured or semi-structured. Works well with Synapse and Power BI.
Lakehouse (delta, Fabric, or databricks)
Unifying data lakes and warehouses for advanced analytics and business intelligence. The medallion architecture is a well-known design for raw data to land in the lake (bronze), cleansed and enriched in curated layers (silver/gold), and served via SQL endpoints.
Semantic models (tabular models or business layer)
Business-facing layer commonly used in Power BI and Fabric - even SSAS where utilised. The model defined measures, hierarchies, and KPIs on top of existing data models to ensure consistency.
Data pipeline engineering
Data pipelines orchestrated with Azure Data Factory and Synapse ensure seamless data movement, staging, and transformation. Metadata-driven frameworks and JSON-based mappings reduce engineering overhead, making pipelines adaptable, automated, and scalable to evolving business needs across structured and semi-structured sources.
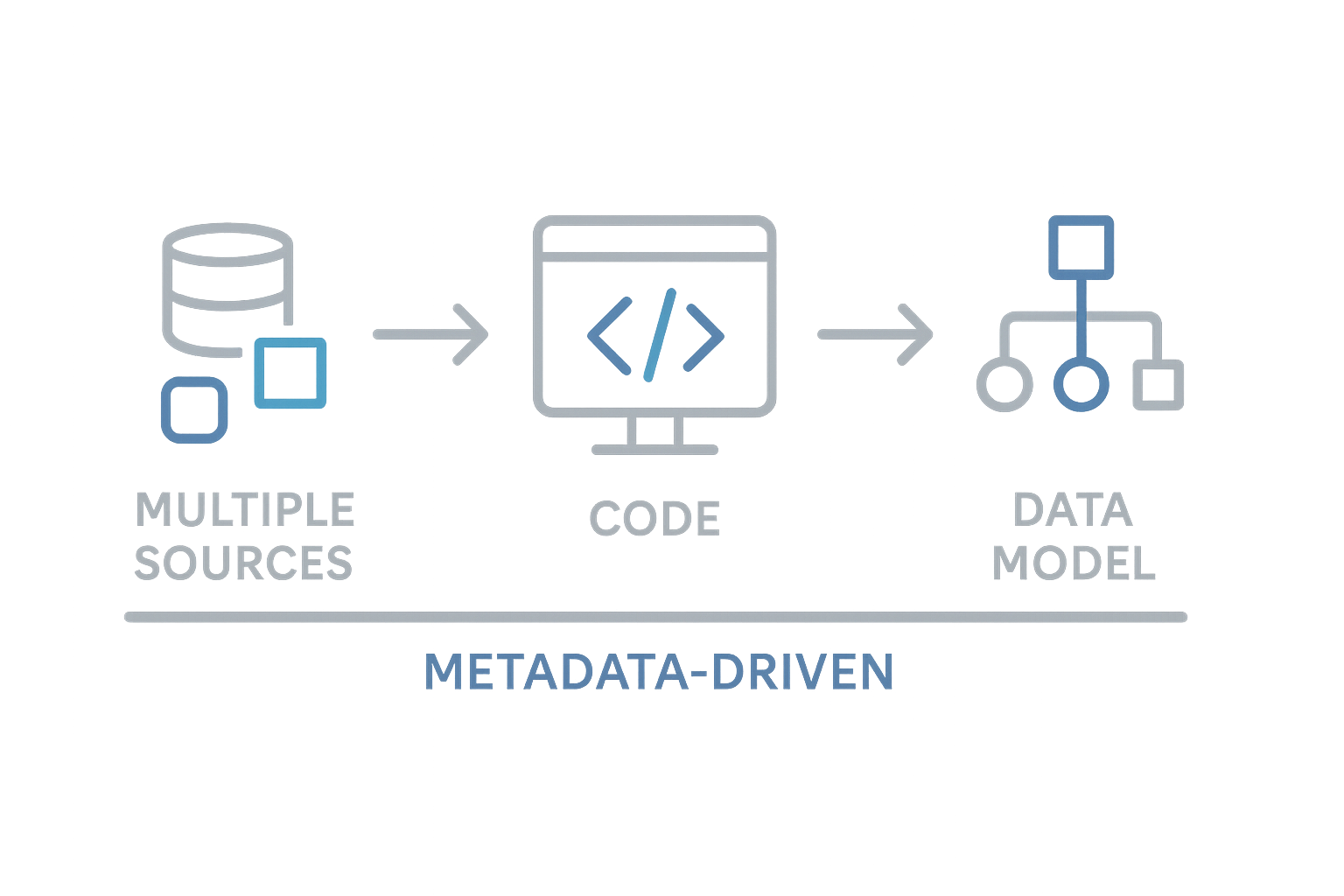
Metadata-driven pipelines
We design and implement metadata-driven pipelines on Azure that adapt dynamically to business rules and data requirements. This approach reduces repetitive coding, increases maintainability, and accelerates delivery. By embedding intelligence into the pipelines, we enable greater flexibility, scalability, and governance across diverse data sources and transformation processes.
{
"framework": {
"version": "2.4",
"pipeline": "wdm_factories_pipeline",
"active": 1,
"path": "data_warehouse/config/01_delta/tms/01_site/pipelines"
},
"annotations": {
"zone": "bronze",
"schema": "delta",
"table": "tms_01_site_consignment",
...
Load-balance orchestration
Our load-balance orchestration solutions ensure that Azure data workflows run efficiently and reliably, even at enterprise scale. By distributing workloads intelligently across resources, we minimise bottlenecks, optimise performance, and reduce downtime. This results in resilient data operations that can seamlessly support business-critical analytics and machine learning initiatives.
Development accelerators
We leverage development accelerators, prebuilt frameworks, reusable components, and proven methodologies, to speed up delivery on Azure projects. These accelerators reduce repetitive effort, improve quality, and ensure consistency across solutions. This results in faster time-to-value, lower costs, and scalable solutions that evolve seamlessly with business requirements.
Indicator - build time (hours)
from pyspark.sql import functions as F
df = (spark.table("maintenance.performance_indicators")
.where(F.col("indicator") == "build_time_hours")
.select("baseline","with_accelerator","abs","improve_percentage","p90_percentage","projects")
)
// build_time_hours
// baseline - 40
// with_accelerator - 24
// Δ (abs) - 16
// improve_percentage - 40%
// p90_percentage - 55%
// projects - 12
Indicator - manual coding hours / weeks
from pyspark.sql import functions as F
df = (spark.table("maintenance.performance_indicators")
.where(F.col("indicator") == "manual_coding_hrs_wk")
.select("baseline","with_accelerator","abs","improve_percentage","p90_percentage","projects")
)
// manual_coding_hrs_wk
// baseline - 20
// with_accelerator - 8
// Δ (abs) - 12
// improve_percentage - 60%
// p90_percentage - 70%
// projects - 10
Indicator - pipeline success percentage
from pyspark.sql import functions as F
df = (spark.table("maintenance.performance_indicators")
.where(F.col("indicator") == "pipeline_success")
.select("baseline","with_accelerator","abs","improve_percentage","p90_percentage","projects")
)
// pipeline_success
// baseline - 92
// with_accelerator - 98
// Δ (abs) - 6
// improve_percentage - 6.52%
// p90_percentage - 8%
// projects - 15
Indicator - post-release defects
from pyspark.sql import functions as F
df = (spark.table("maintenance.performance_indicators")
.where(F.col("indicator") == "pipeline_defects")
.select("baseline","with_accelerator","abs","improve_percentage","p90_percentage","projects")
)
// pipeline_defects
// baseline - 10
// with_accelerator - 6
// Δ (abs) - 4
// improve_percentage - 40%
// p90_percentage - 50%
// projects - 9
Indicator - infrastructure costs (£/month)
from pyspark.sql import functions as F
df = (spark.table("maintenance.performance_indicators")
.where(F.col("indicator") == "infra_cost")
.select("baseline","with_accelerator","abs","improve_percentage","p90_percentage","projects")
)
// infra_cost
// baseline - 8000
// with_accelerator - 6500
// Δ (abs) - 1500
// improve_percentage - 18.75%
// p90_percentage - 25%
// projects - 7
Analytics and business intelligence
Analytics and BI deliver actionable insights through optimised dimensional models in Synapse and governed Power BI semantic layers. Faster ingestion cycles and improved query performance provide timely, trusted, and consistent reporting to support executive decisions and self-service analytics adoption.

Microsoft Fabric
We deliver solutions on Microsoft Fabric that unify data integration, engineering, and analytics into a single platform. By leveraging its end-to-end capabilities, we help organisations simplify complex data landscapes, accelerate insight generation, and improve governance, all within a scalable, cloud-native ecosystem built for enterprise performance.
Confident with PySpark?
from pyspark.sql.functions import col, current_timestamp, when
bronze = spark.read.format("delta").load("Files/lakehouse/bronze/tms/site/consignment")
silver = (
bronze
.withColumn("ingested_at", current_timestamp())
.withColumn("status", when(col("delivered") == True, "Delivered").otherwise("InTransit"))
)
(silver.write
.format("delta")
.mode("overwrite")
.option("overwriteSchema", "true")
.save("Tables/silver/tms/site/consignment_curated"))
Prefer SQL?
With Fabric, use the skills you know to build the data solutions you need
SELECT
site_id,
COUNT(*) as total_consignments,
SUM(CASE WHEN status = 'Delivered' THEN 1 ELSE 0 END) AS delivered,
CAST(SUM(CASE WHEN status = 'Delivered' THEN 1 ELSE 0 END) * 1.0 / COUNT(*) AS DECIMAL(5,2)) AS delivery_rate
FROM OPENROWSET(
BULK 'tables/silver/tms/site/consignment_curated',
DATA_SOURCE = 'OneLake',
FORMAT = 'DELTA'
) WITH (
site_id INT,
status NVARCHAR(32)
) AS d
GROUP BY site_id;
Power BI
Our team designs and develops Power BI solutions that transform data into clear, actionable insights. We build intuitive dashboards, interactive reports, and advanced analytics that empower decision-makers at every level. With a focus on usability and scalability, we ensure Power BI becomes a true driver of business intelligence.
Power Automate
We implement Power Automate workflows that streamline business processes and eliminate repetitive tasks. By connecting Azure data services with everyday applications, we create automation solutions that improve efficiency, reduce human error, and free up teams to focus on higher-value work. The result is a more agile, productive organisation.
Looking to fast-track your journey to Microsoft Fabric?
We collaborate with your team to design a fit-for-purpose Microsoft Fabric solution that meets your needs and proves the value of a truly unified analytics platform. By working closely with Microsoft and strategic partners, we accelerate your journey to Fabric and deliver measurable impact faster.
Data governance and security
Azure ensures enterprise-grade governance and security with role-based access, data lineage, auditing, and monitoring. Integration with Microsoft Purview enhances data discoverability, cataloging, and compliance, while managed identities safeguard pipelines and storage, delivering a secure and trusted data ecosystem.

Governance framework
We establish governance frameworks that define clear policies, roles, and controls for managing enterprise data on Azure. Our approach balances agility with compliance, ensuring data is accessible yet secure. By embedding governance into workflows, we help organisations build trust, maintain regulatory alignment, and maximise the value of their data assets.
Microsoft Purview
We implement Microsoft Purview to provide end-to-end visibility and control over organisational data. From discovery and classification to lineage and access management, Purview enables consistent governance across hybrid and multi-cloud environments. Our solutions ensure that data is not only compliant but also discoverable, trustworthy, and ready for business use.
Migration and modernisation
We help organisations migrate and modernise their data platforms using Azure’s cloud-native services. From secure data migration to modern architectures like Synapse, Fabric, and Data Lakehouse, we ensure scalability, cost efficiency, and faster insights, transforming legacy systems into agile, future-ready solutions.

Migration to Synapse (Serverless or Dedicated)
We guide organisations through seamless migrations to Azure Synapse, whether serverless for flexibility or dedicated for enterprise-scale performance. Our approach ensures data is moved securely, optimised for cost and speed, and structured for analytics readiness, delivering a modern data warehouse that scales with your business needs.
Migration to Fabric
We help organisations migrate to Microsoft Fabric, consolidating data integration, engineering, and analytics into a unified platform. Our expertise ensures smooth transition with minimal disruption, while optimising for governance, performance, and scalability. The result is a modern, end-to-end data estate built to accelerate insight and innovation.
Future-proof design
Our solutions are architected with the future in mind, scalable, adaptable, and ready to embrace new technologies. By combining best practices with modern cloud-native approaches, we design systems that evolve with business needs. This ensures long-term value, resilience, and the ability to leverage emerging innovations without costly redesigns.
Delivery models tailored to your project
We offer flexible delivery models designed to align with your unique project requirements. Whether you need resource augmentation, dedicated project teams, or a hybrid approach, we adapt to your context and goals. Our focus is on efficiency, collaboration, and delivering outcomes that create measurable value.
Resource augmentation
Extend your team with skilled experts, seamlessly integrated support.
3+ MonthsOutsourced project
End-to-end delivery of defined initiatives with accountable ownership.
Short- to Medium TermStrategic data partner
Long-term collaboration to unlock data-driven business growth.
Long-termAssessment and scoping
Evaluate requirements, define scope, ensure project alignment.
1+ SprintJumpstart
Accelerate adoption with rapid, structured onboarding and enablement.
2+ SprintsOn-Demand support
Flexible expertise available whenever challenges or needs arise.
Tailored